Simple Linear Regression
2023-10-23
Always visualized before you model
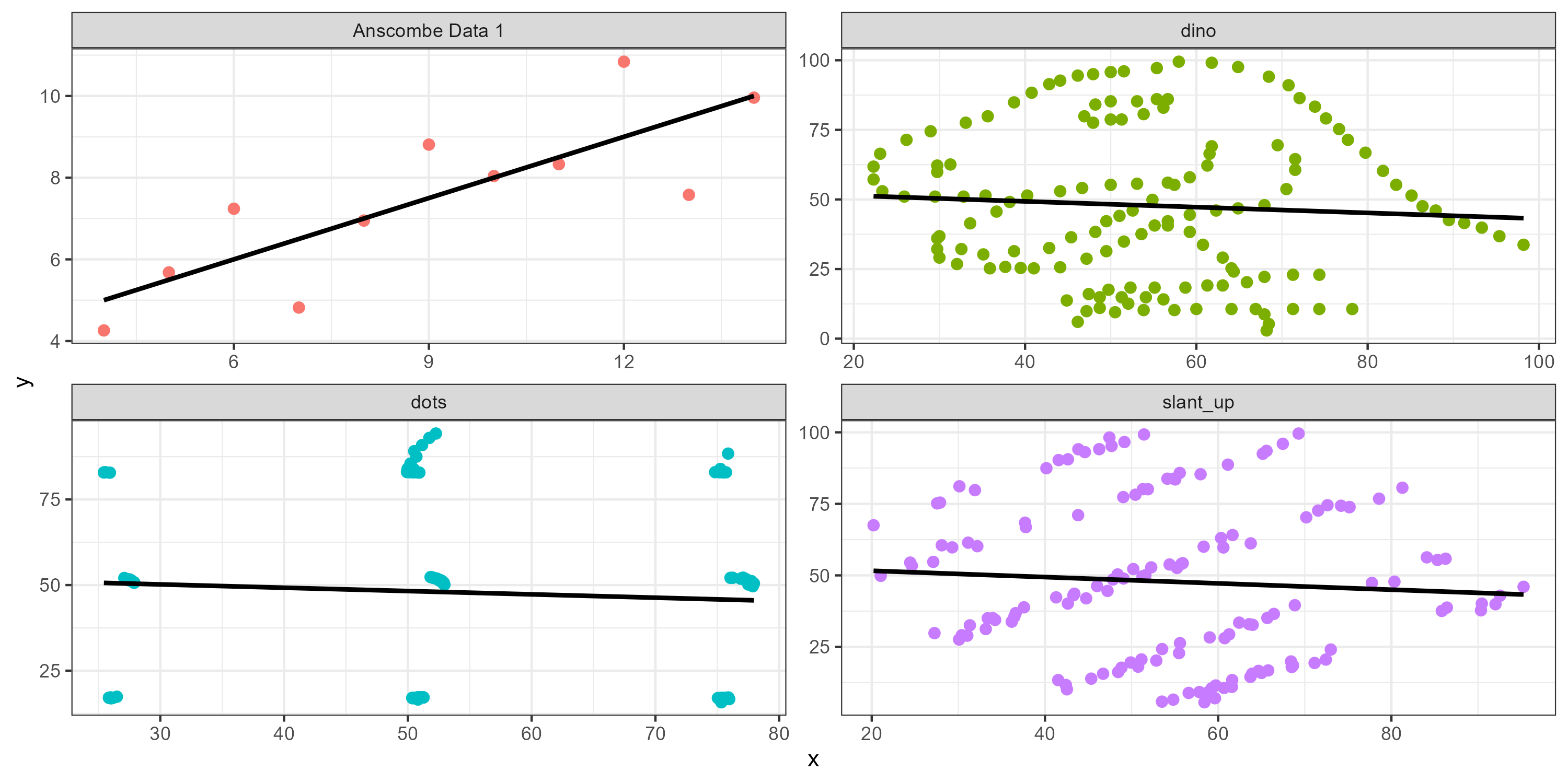
Anscombs Quartet are four datasets have the same correlation value and similar slope of the regression line.
So does this datasaurus!
2. Visualize and summarise bivariate relationship

There is a strong, positive, mostly linear relationship between the body mass (g) of penguins and their bill length (mm) (r=.595).
Assumption: Normality of residuals

Assumption: Normality of residuals

This is also known as a ‘normal probability plot’ or a ‘qqplot’. It is used to compare the theoretical quantiles of the data if it were to come from a normal distribution to the observed quantiles. PMA6 Figure 5.4 has more examples and an explanation.
Assumption: Homogeneity of variance

Model-check Posterior Predictions

This check compares the distribution of predicted values to the distribution of observed values. In this example the observed distribution of bill length is bimodal, and so the model is overestimating some values and underestimating others. There is clearly some other confounding variable that predicts bill length better than just body mass.