Show the code
2025-10-22
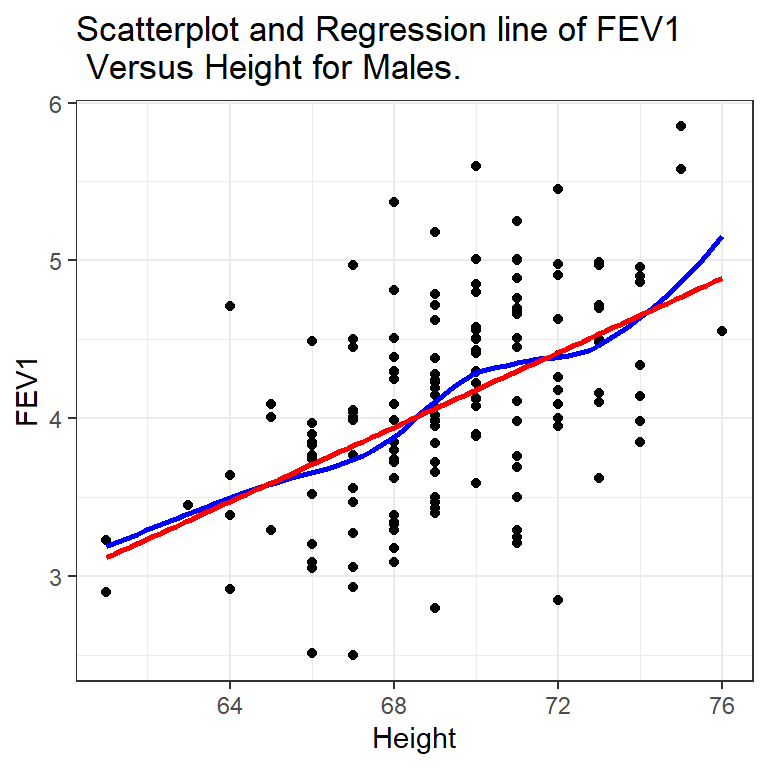
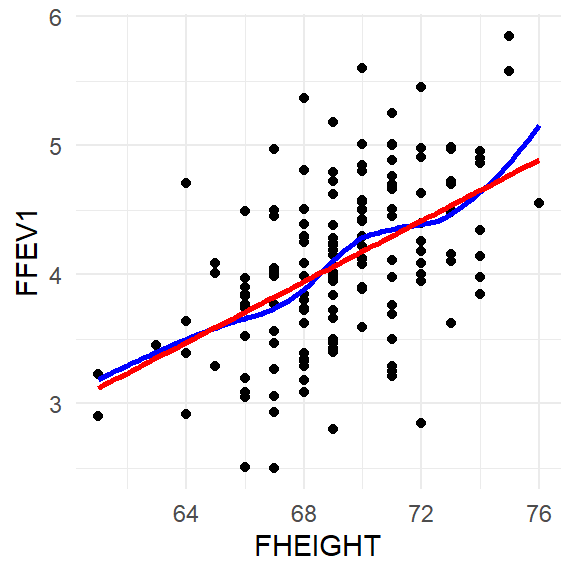
There does appear to be a tendency for taller men to have higher FEV1. Since this relationship is reasonably linear (the blue loess line is similar to the red linear line) we can write the model the population average FEV \(\mu_{y}\) as a linear function of height \(x\):
\[ \mu_{y} = \beta_{0} + \beta_{1}x \]
The intercept parameter, \(\beta_{0}\), represents where the line crosses the y-axis when \(x=0\). The slope parameter, \(\beta_{1}\), represents the change in \(\mu_{y}\) per 1 unit \(x\).
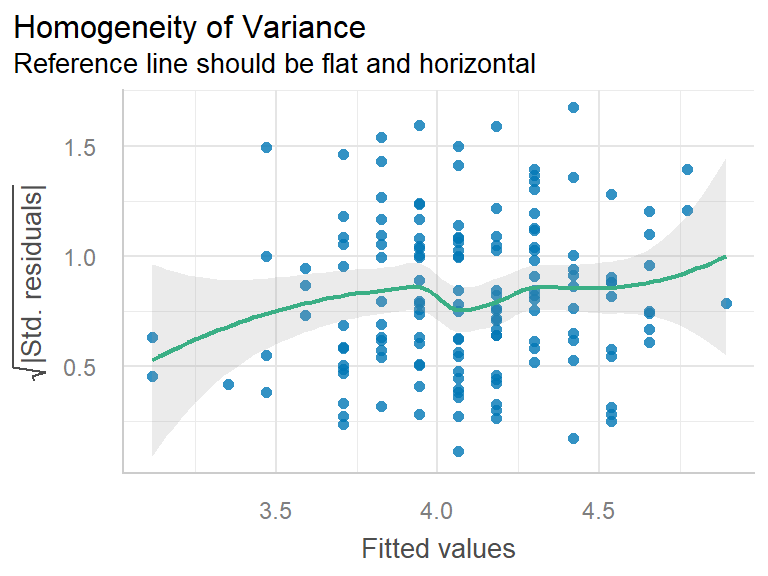
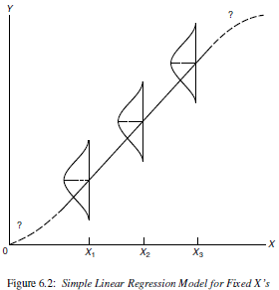
The mathematical model that we use for regression has these features that translate into assumptions.
\[ \begin{align} Y|X & \sim N(\mu_{Y|X}, \sigma^{2}) \\ \mu_{Y|X} & = \beta_{0} + \beta_{1} X \\ \sigma^{2} & = Var(Y|X) \end{align} \]
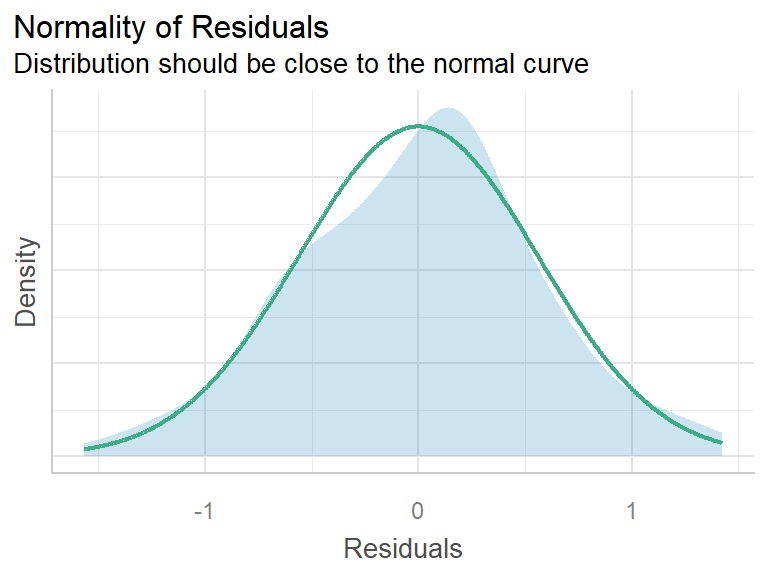
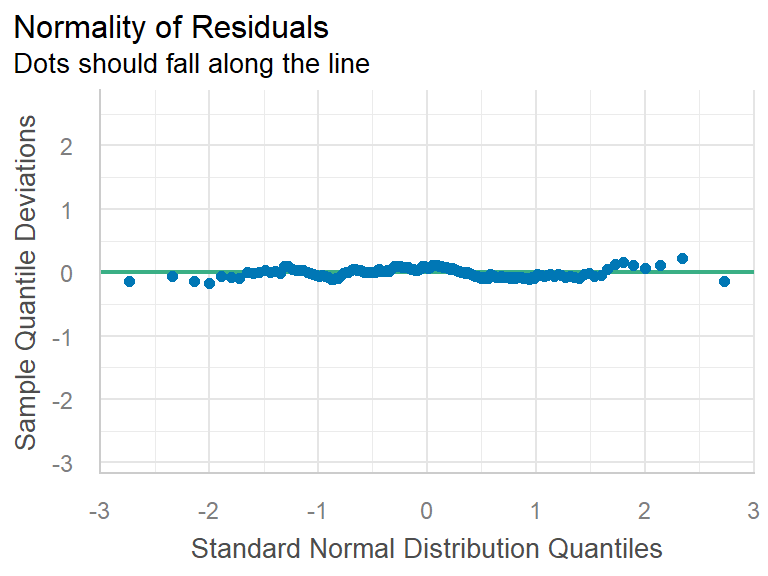
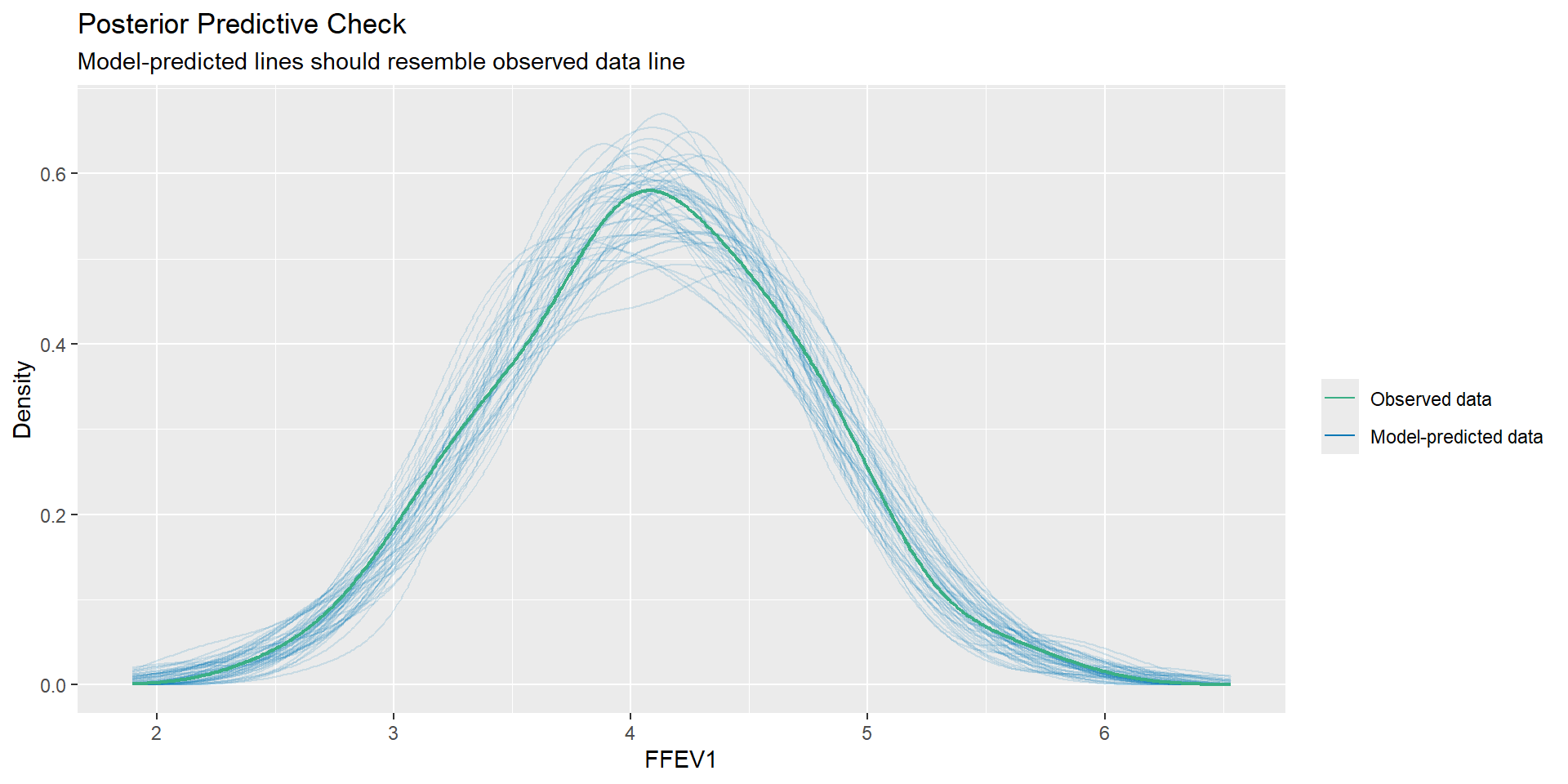
These plots are generated from the performance package.
Caution!
The linear model is only valid within the range of the data used to fit the model
To take an extreme example, suppose a father was 2 feet tall. Then the equation would predict an impossible negative value of FEV1 (\(-1.255\)).
A safe policy is to restrict the use of the equation to the range of the \(X\) observed in the sample.